Product Updates
What Makes Modern Voice Agents Feel ‘Human’? The S2S Secret Explained

Date
September 16 2025
Author
Shivani Patel
Voice Agents, Unfiltered: How Real-Time S2S Is Redefining the Future of Voice AI Startups
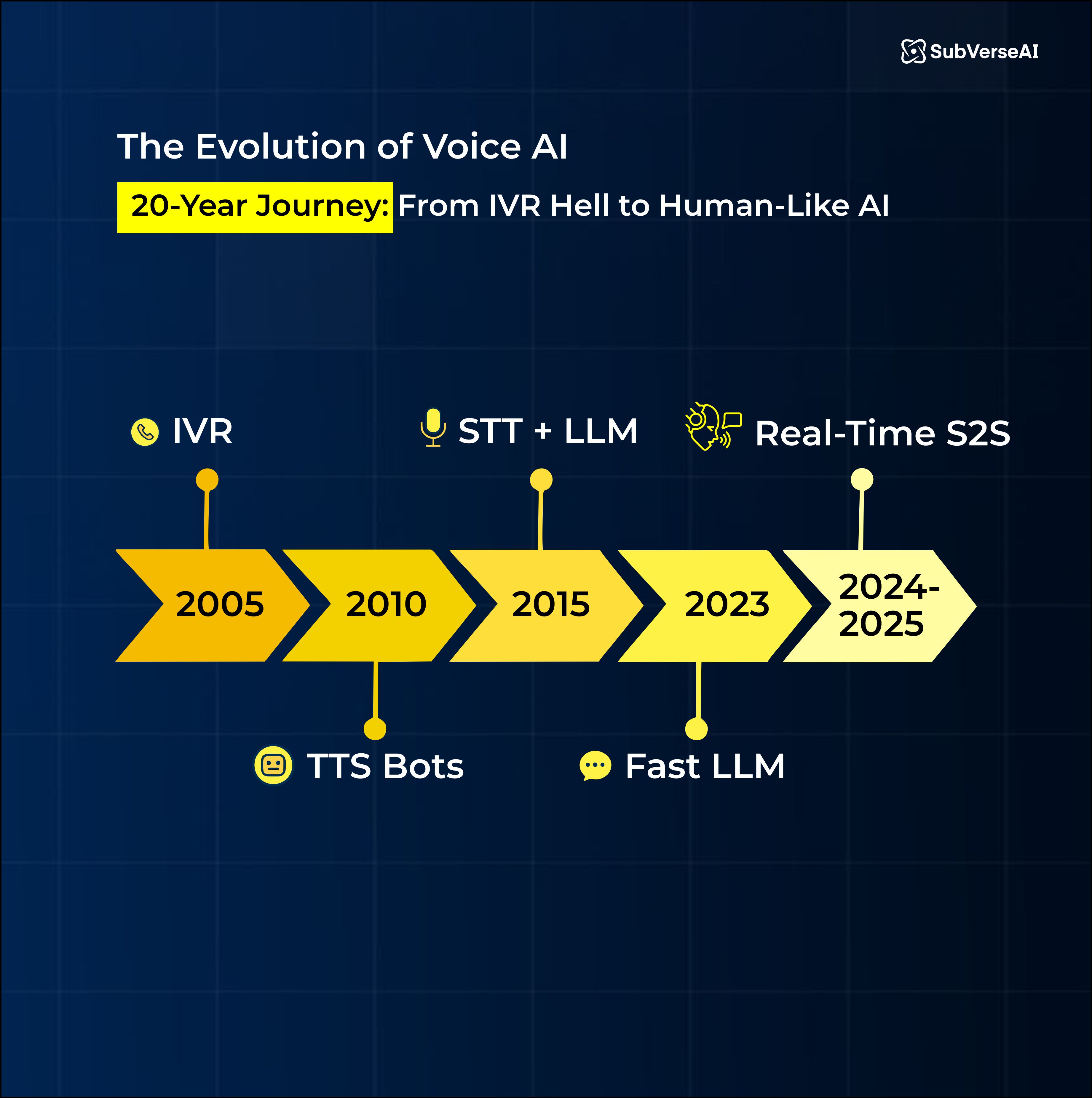
Voice AI has come a long way from those rigid, robotic systems that sounded like they were reading tax forms out loud. Today’s best AI voice agents feel conversational, emotionally aware, and sometimes surprisingly human.
So what’s powering this shift?
A new generation of real-time speech to speech (S2S) models that are transforming how modern voice AI startups build fast, natural, and intelligent voice agents.
Let’s break down the tech, the magic, and the messy truth behind these new-age conversational systems.
From Clunky Pipelines to Real-Time Streaming
The moment you say “Hey!” to a voice agent, the processing begins. But not all systems handle that moment the same way.
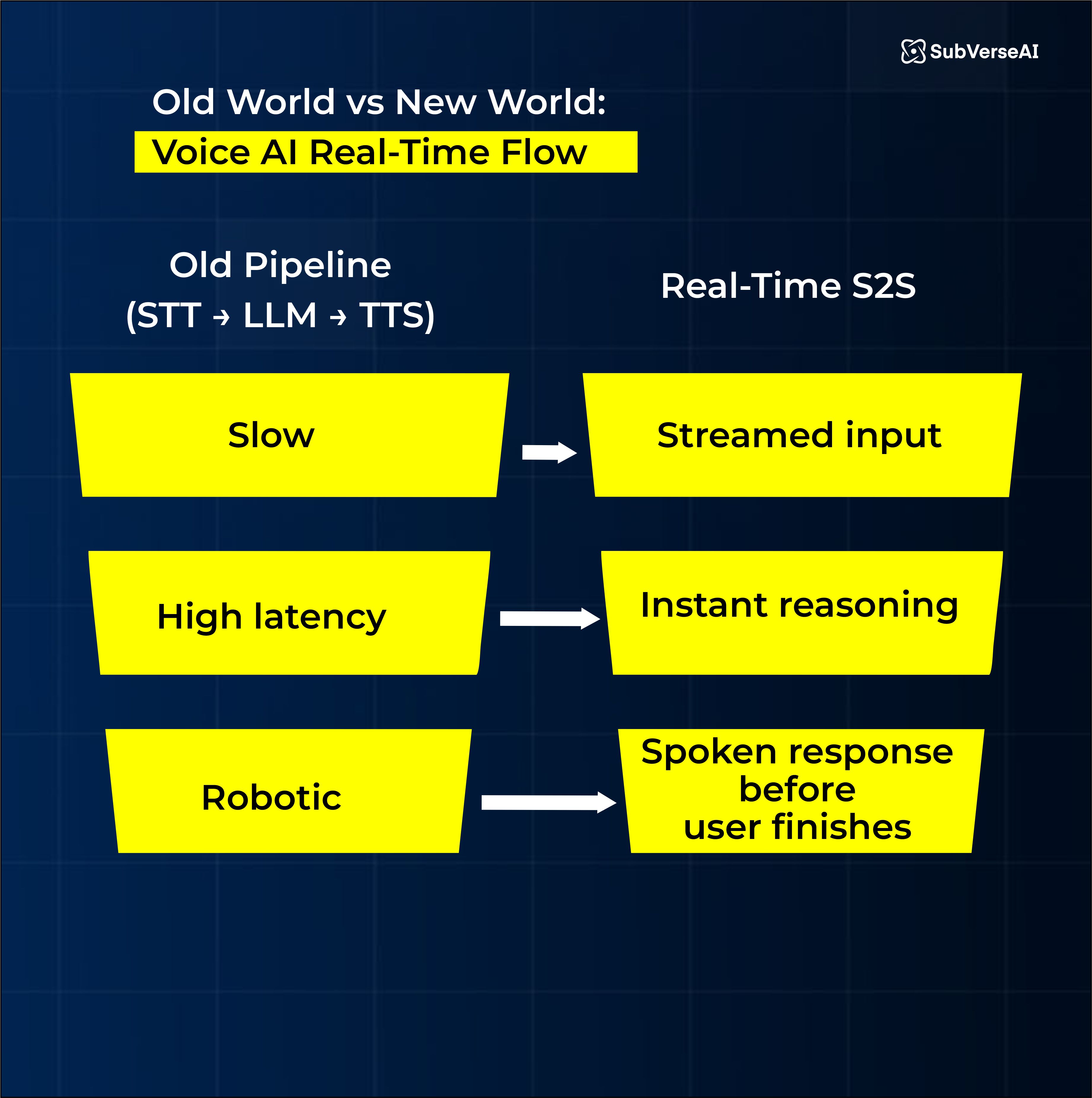
Old World: The 3-Step Pipeline
Most traditional voice AI pipelines looked like this:
STT (Speech-to-Text)
LLM / NLU Processing
TTS (Text-to-Speech)
Effective, reliable, but slow. Each step was its own bottleneck, turning the whole thing into a relay race with mediocre runners.
New World: Real-Time S2S
Real-time S2S models from platforms like OpenAI Realtime and Google Gemini Live skip the slow relay and treat audio like a continuously flowing stream. As you speak:
Your partial audio is transcribed
The model begins reasoning instantly
A response is generated - before you even finish talking
Why Real-Time S2S Models Feel So Human
Real-time S2S is unlocking use cases that older pipelines simply couldn’t support.
1. Emotion-Driven Responses
S2S models can adapt tone - warm, cheerful, calm, authoritative - on the fly.
Perfect for tutors, coaches, sales agents, or even customer support.
2. Multilingual Flexibility
Switch between Hindi, Tamil, English, and more - mid-conversation.
Great for hyperlocal SaaS products and voice AI startups building global-ready experiences.
3. Ultra Low Latency
Minimal delay = no awkward pauses, no robotic turn-taking.
Feels more like a natural conversation and less like a questionnaire.
If you've used a modern AI tutor or a “rapid response" support bot, you’ve already felt the difference.
But… S2S Isn’t Perfect (Yet)
Even the best real-time voice AI systems stumble. Here’s where:
1. Not Great at Complex, Multi-Step Logic
Need API calls, database writes, or procedural workflows?
The classic STT → LLM → TTS pipeline still wins.
2. Function Calling Is Still Emerging
Real-time models prioritize fluency over precision, which can lead to misfires when strict business logic is involved.
3. Highly Sensitive to Overlaps & Noise
Cross-talk, accents, and background chaos can still trip them up more than text-first workflows.
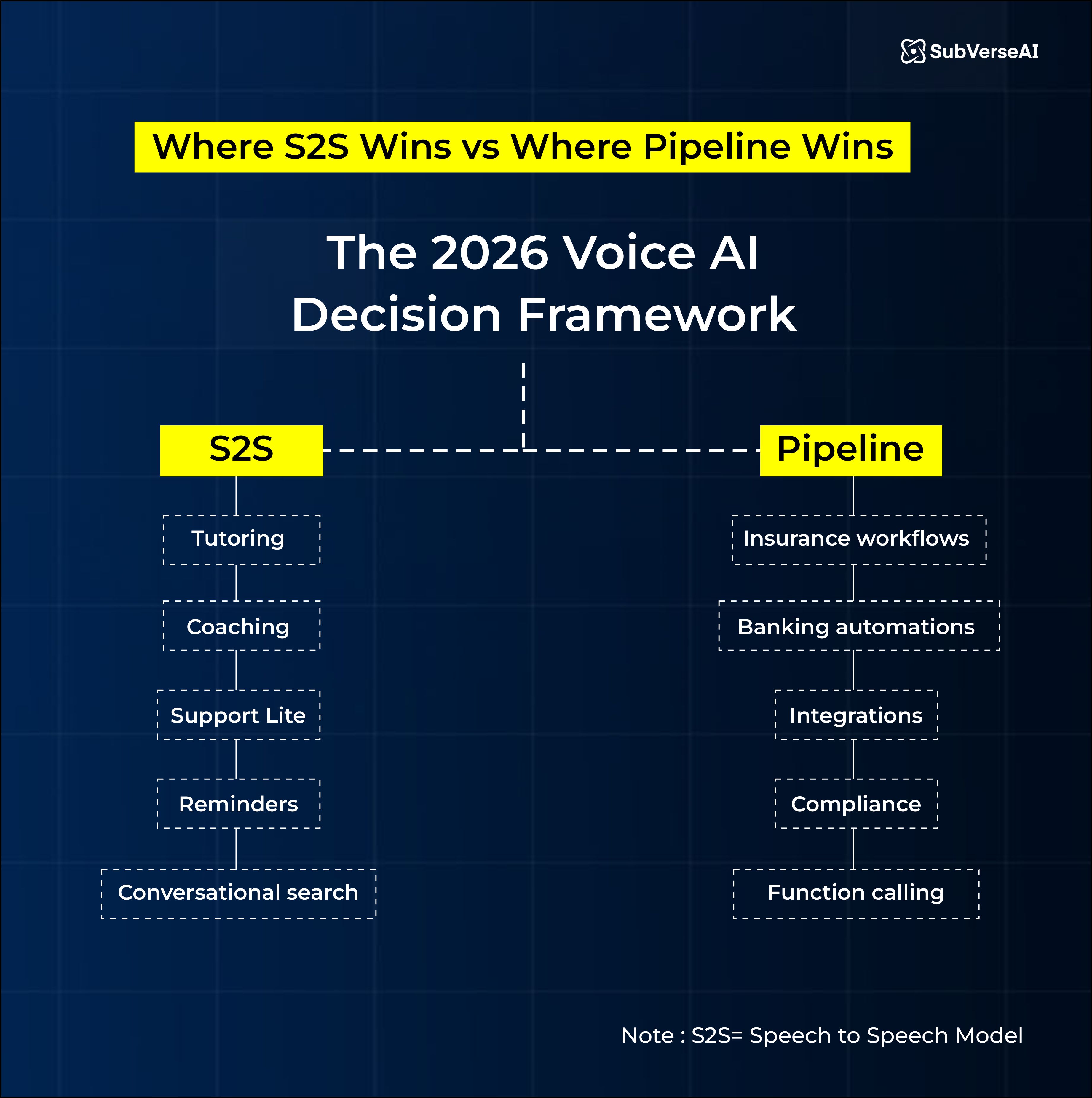
When to Use Real-Time S2S vs a Traditional Pipeline
Go S2S When Your Use Case Needs:
Fast back-and-forth
Emotional nuance
Bi-directional conversation
Natural, continuous speech
Best fits:
✔ AI tutoring
✔ Coaching or therapy bots
✔ Lightweight support
✔ Booking, reminders, simple tasks
✔ Conversational search
Stick to Pipeline When It’s About:
Multi-step workflows
Backend integrations
Function calling
Escalations and precision
Compliance-heavy environments
Best fits:
✔ Insurance workflows
✔ Banking automations
✔ Enterprise integrations
✔ Voice agents that trigger actions
The Bottom Line: Where Voice AI Is Heading
Real-time S2S models aren’t just another upgrade they are reshaping the entire playbook for how voice AI startups build conversational products.
With platforms like OpenAI and Google pushing boundaries and infrastructure tools like LiveKit enabling high-quality streaming, we’re entering an era where:
AI agents speak like humans
Respond like humans
And increasingly think like humans in real-time
At SubVerse AI, we’re bringing that future into production - supporting real-time S2S models, streaming pipelines, and hybrid architectures so businesses can build voice agents that feel genuinely alive.
Next time you talk to an AI and it feels “just right,” you’re experiencing the result of a deeply engineered conversation - designed to sound effortless.






More Blogs
Stay ahead with the newest advancements in AI automation. Discover productimprovements, feature releases,
